Technical Quick Start Guide
Thank you for your interest in the Unicode Consortium! This Technical Quick Start Guide provides information on how you can get involved and contribute to internationalization and the technical projects of the Unicode Consortium.
What is Internationalization and Why Does it Matter?
To ensure that end users can seamlessly work, collaborate, communicate, and much more in their native languages around the world, software developers deploy the Unicode architecture and standards across all software and services.
Internationalization (aka ‘i18n’) is the design and development of a product that is enabled for target audiences that vary in culture, region, or language. Internationalizing your software means you can support across different regions and languages in the way humans expect to interact with an application – including the presentation of text, numbers, dates, etc., plus the layout of the user interface.
Localization is the adaptation of software for specific languages and cultures. Typically, this involves providing translations or providing alternate, locally-acceptable content such as stylesheets or images. Internationalized software makes localization very efficient.
Unicode establishes the foundational layers (character set, locale data, algorithms) that make it possible to design code that handles the requirements of all languages and regions at the same time, while minimizing the need for lower-level details and quirks to interfere with that design.
Architect once for a global solution that supports local implementations.
You can learn more about internationalization here.
What is Unicode?
The Unicode Consortium is the premier standards organization for internationalization of software and services, including the encoding of text for all modern computing systems. The Consortium supports internationalization with the Unicode Standard and by providing core libraries, software algorithms, and structured data.
The Unicode Standard refers to the standard character set that represents all natural language characters. Unicode can encode up to roughly 1.1 million characters, allowing it to support all of the world’s languages and scripts in a single, universal standard.
All modern operating systems, computing environments, programming languages, and applications support the core of the Unicode Standard. Since the Unicode Standard specifies the handling of characters for all languages in a uniform way, it simplifies and enables locale-sensitive i18n algorithms that wouldn’t be possible otherwise, such as:
- Sorting and string searching/matching
- Word-/sentence-boundary detection and line breaking
- Right-to-left text region boundary analysis
- Formatting of numbers, times, lists, and plural messages
There are many more features supported by Unicode data and libraries. Higher level computing applications rely upon these features to achieve their goals. Examples include products like web browsers and text editors, and services based on natural language processing like machine translation and voice assistants.
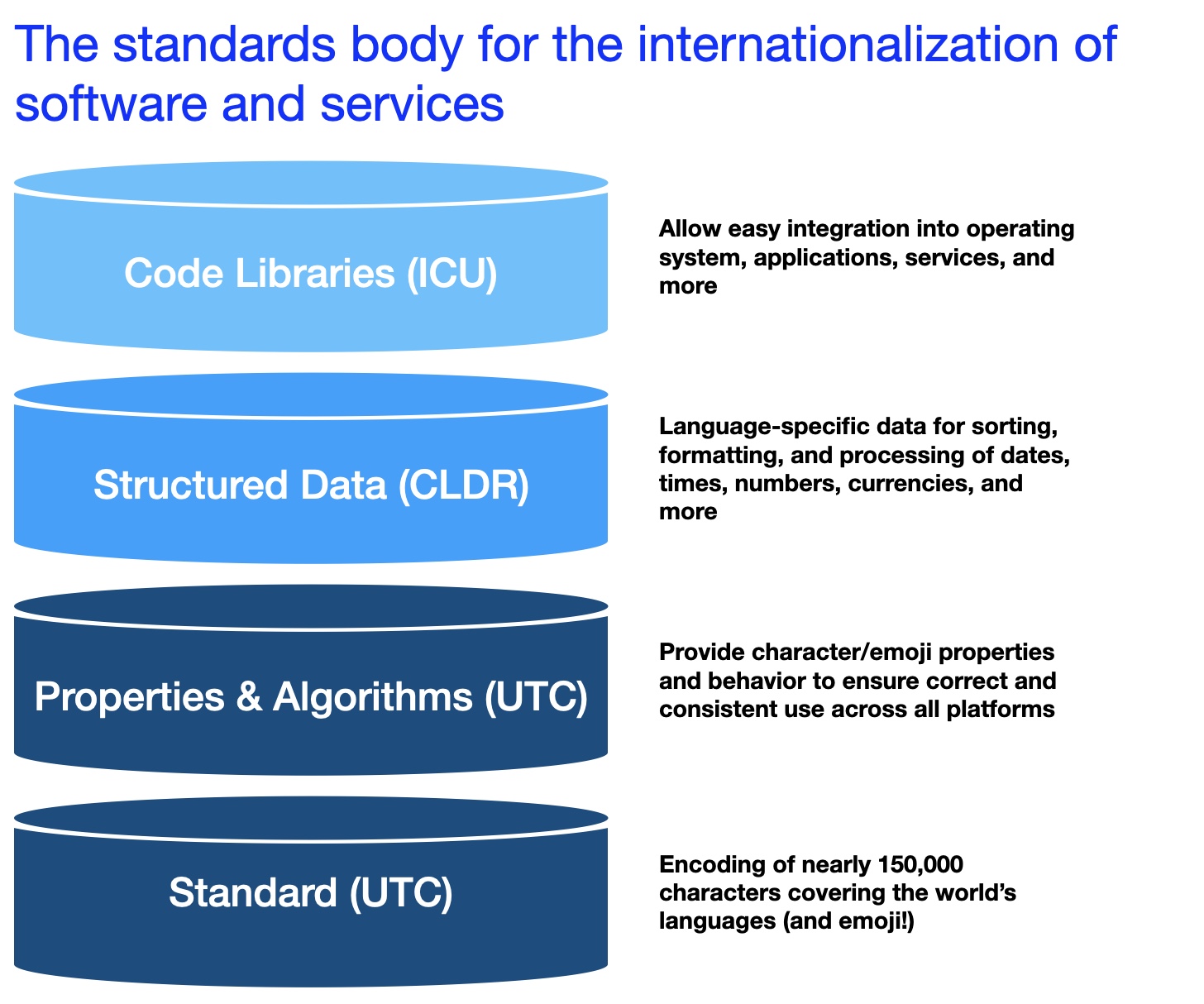
Diagram: What is Unicode? Credit: Unicode Consortium
Overview of Technical Committees and Unicode Projects
The Unicode Technical Committees carry out the technical work of the Consortium. The participants in the Committees are sources of distinguished expertise on all aspects of internationalization, multilingual and multiscript systems, and bring together key players and new talent in software internationalization.
Our projects support:
- Developing language standards, software algorithms, and data to ensure interoperability in content and interchange of text.
- Meeting the needs of industry and users by adding new characters, including emoji, ideographs, symbols, unencoded scripts for languages.
- Incorporating Unicode into other standardization efforts: international and industry standards, protocols, data formats, software security policies, etc.
The foundational base of Unicode is the Unicode Standard, which defines characters (including emoji) and scripts. It also provides properties that ensure the characters behave as expected on platforms.
Unicode’s programming libraries include ICU (International Components for Unicode) and ICU4X. Unicode supports structured data with its CLDR (Common Locale Data Repository) project. ICU and CLDR have become the de facto standards for internationalization functionality and localization data respectively. These libraries are open-source and available for download here.
ICU provides support for character and text processing, localized formatting of data (date-time, numbers, etc.), message formatting, linguistic sorting, and many other capabilities necessary for software internationalization. ICU is available for C/C++, Java, and has wrappers for 18 other programming languages.
Developers use ICU to ensure text is properly encoded and can be universally interchanged, that data such as dates and numbers are formatted to local customs, and that text messages are localized and conform to native grammar rules, among many other capabilities necessary for multilingual software. Check out the ICU user guide to learn about using ICU.
ICU4X provides ICU features for client-side, resource-constrained environments in Rust and other programming languages. For an introduction to the project, please take a look at the Introduction to ICU4X for Rust tutorial. For technical information on how to use ICU4X, visit the project’s API docs.
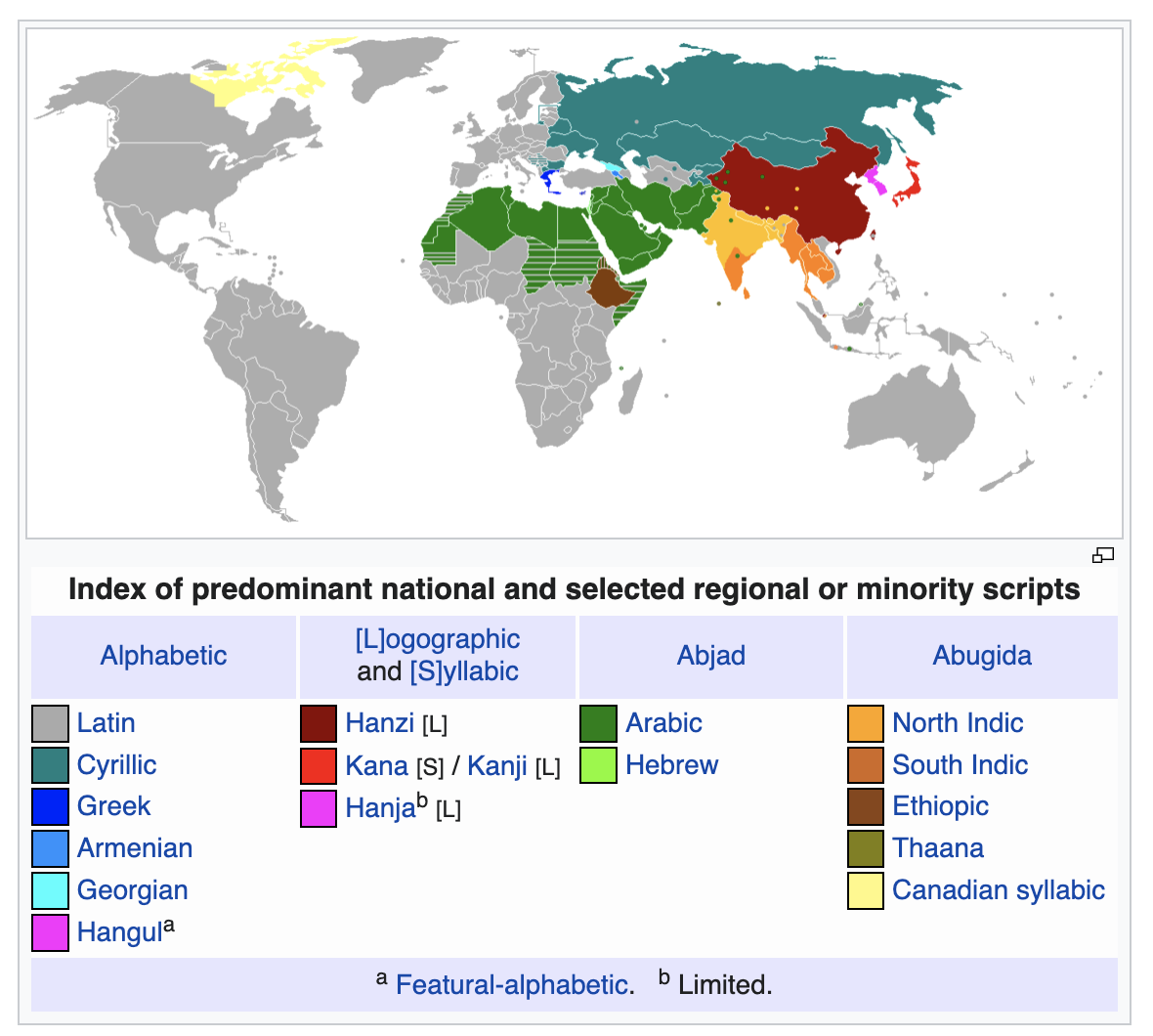
Diagram: Index of predominant national and selected regional or minority scripts. Credit: From Wikipedia
The Unicode Common Locale Data Repository (CLDR) provides key language data for software to support the world’s languages, with the largest and most extensive standard repository of locale data available. This data is used by a wide spectrum of companies for their software internationalization and localization, adapting software to the conventions of different languages for such common software tasks.
CLDR provides data for Locale-specific patterns for formatting and parsing, translations of region/country names, language and script information, etc. and is distributed in several formats including XML, LDML and JSON. It can be downloaded here.
CLDR data is also bundled into ICU, which provides functionality powered by CLDR data to support internationalization best practices as they evolve. Software that bundles ICU will automatically inherit the vast expertise that goes into the CLDR data and ICU algorithms.
To learn more, check out Unicode’s Technical FAQ.
Who should participate and volunteer?
The Consortium welcomes all stakeholders in the language technology ecosystem!
- Technology industry vendors
- Software vendors
- Hardware vendors
- SaaS vendors
- Software developers
- Language infrastructure and application developers
- Localization infrastructure developers
- Machine Translation (MT) and Natural Language Processing (NLP) developers
- Font and input developers
- Subject Matter Experts
- Internationalization subject matter experts
- Linguists and researchers
- Program and Product Managers
- Language technology program and product managers
- Community Managers
- Language communities
- Technology Evangelists
- Localization
- Translators and localizers
- Localization vendors
- User Experience Designers
- Emoji designers
- UX / UI designers
- Partners
- Governments
- Academia
- International agencies
- End-users
- SaaS users
- Mobile and Web users
Useful Links for Getting Involved
- Unicode Consortium
- Unicode Consortium Technical Site
- General Technical Committee Procedures
- Technical Committee Meeting Calendar
- CLDR Technical Committee
- CLDR Digitally Disadvantaged Languages Subcommittee
- CLDR Message Format Subcommittee
- CLDR Keyboards Workgroup
- CLDR Person Names Workgroup
- ICU Technical Committee
- Unicode Technical Committee (UTC)
- Unicode Technical Committee Chairs
- Unicode GitHub Repositories
- Bi-directional annex (UAX #9)
- Anti-spoofing
Third-party links
- Internationalization (W3C)
- Unicode BiDi Basics (W3C)
- Unicode Consortium (ISO)
Unicode Project Mailing Lists and Contacts
Some Video Resources
How can my organization or I become a member?
As a member of the Unicode Consortium, you can productively participate in internationalization standards work. You can help develop and maintain core language technologies using XML, Java, and other tools.
It’s easy to join as a member of the Unicode Consortium. Being a member enables you to participate in the Unicode standard, technical language projects, language locale data projects as well as interact with some of the leading language technology experts in the world.